第八章 高性能服务器程序框架
本章意在抛出一些核心的概念, 实操基本没有, 但是这些概念的理解我认为相对重要, 我会以口语化的形式简要描述.
服务器模型
- C/S模型 : 客户端/服务端, 最基础的服务器模型, 资源集中在服务端, 主要是客户端向服务端申请资源.
- p2p模型 : 每个主机都可以是客户端和服务端, 每个主机上都会存有一定的资源, 每个主机利用洪泛向每个点申请资源.
服务器编程框架
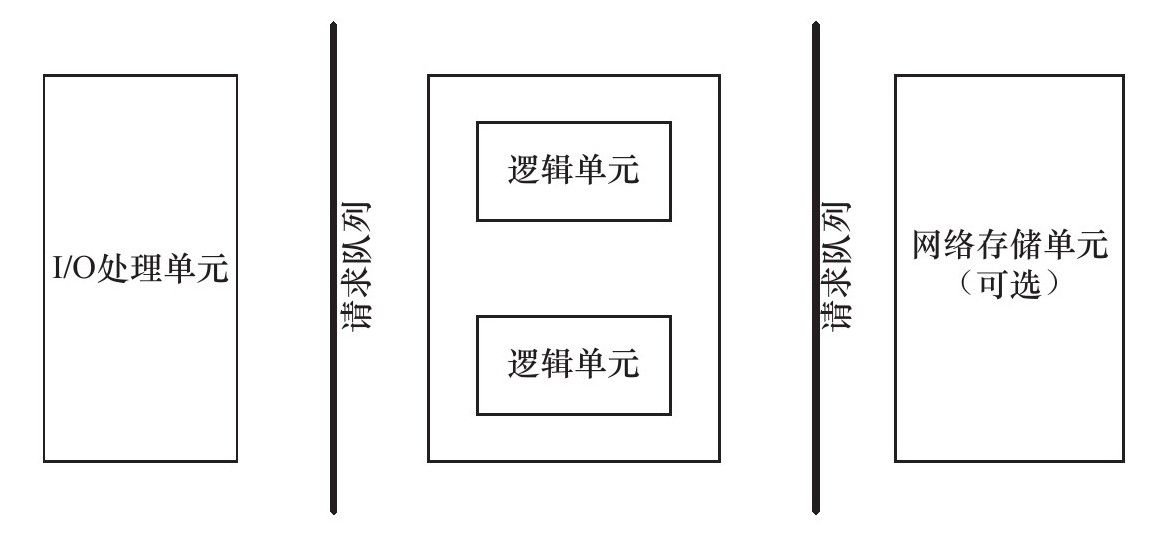
- I/O处理单元 : 用于处理客户连接, 实现负载均衡, 可以用主线程实现, 也可以直接用Nginx.
- 逻辑单元 : 一般是一个进程或线程, 一般用于处理核心逻辑, 也可进行数据的收发(依事件处理模式而定).
- 网络存储单元 : 就是数据库, 比如mysql.
- 请求队列 : 就是以上三者之间通信方式的抽象, 一般用池实现, 里面存放已经建立好的TCP连接.
I/O模型
其实就在确定数据在收发时是阻塞还是非阻塞, 是同步还是异步.
阻塞和非阻塞属于数据准备阶段, 是系统IO操作的就绪状态.
同步和异步属于数据读写阶段, 是应用程序和内核的交互方式.
阻塞 : 在IO操作就绪时, 进程将被阻塞, 等待IO数据收发.
非阻塞 : 在IO操作就绪时, 会立即做出判断, 给出返回值, 退出函数, 通过返回值判断收发是否正常.
同步I/O : 读写操作在IO事件发生之后, 由应用程序本身完成.
阻塞IO / IO复用 / SIGIO信号 都属于同步IO
异步I/O : 读写操作由内核完成, 应用程序只是提前设置缓冲区位置和IO操作完成后的通知函数.
两种高效的事件处理模式
服务器程序通常需要处理三类事件:I/O事件、信号及定时事件。
Reactor模式
这是一种同步IO模式, 其中线程分为主线程和工作线程, 主线程负责监视socket是否有信息发送过来, 工作线程负责读写以及核心逻辑.
简略步骤如下 :
- 主线程通过epoll注册socket的读就绪事件.
- 主线程调用epoll_wait等待注册的socket发来消息.
- 某个socket可读时, 将其分发给工作线程.
- 工作线程进行读取并处理核心逻辑, 如果需要回复, 就用ekpoll注册写就绪事件.
- 主线程也会调用epoll_wait等待写事件.
- 当socket可写时, 主线程再将其分发给一个工作进程进行写操作.

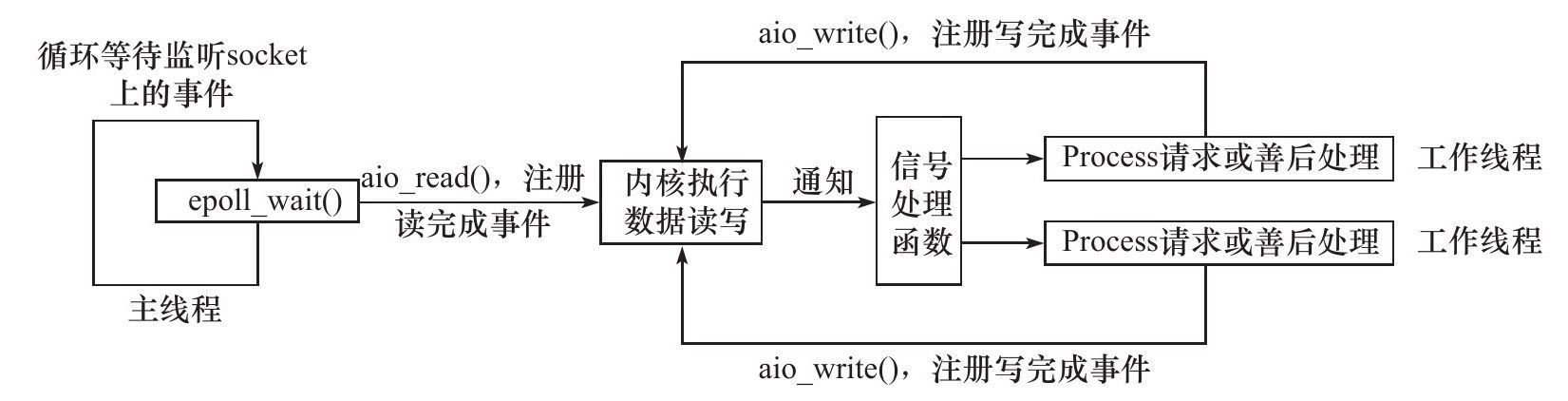
Proactor模式
一种异步IO模式, 基础思想与Reactor模式一直, 但是利用异步IO的机制减去了工作线程的读写工作, 读写工作由内核实现, 只需要设置通知函数唤醒工作线程.
有限状态机
这个名字真的很高端, 但实际有更简单的理解.
这是一个逻辑单元内部的高效编程手法, 可以简单理解为把一个事务分解成多个执行的阶段, 用enum把这些状态列举出来, 再用switch通过判断当前事务状态来分别调用对应的处理函数.
比如我们要对HTTP请求进行读取和分析, http报文有请求行/请求报头/请求正文三个部分, 由于TCP传输一次传输可能不完整, 我们可能读不完全, 我们可以把状态分为请求行读取, 报头读取, 正文读取, 在不同的状态执行不同的读写操作和处理操作. 并且我们也应当设置合理的状态转移, 比如当前状态为请求行读取, 在相关操作处理完后, 那么状态就应当被转化为报头读取.
下面是完整的代码, 确实非常冗长, 上面这一段算是我最精简的概括了, 其实经过求证其实也没有多大必要去详细记住, 因为现在有很多的http库可以解决这方面的问题, 我们主要是重在理解这个概念.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
| #include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#define BUFFER_SIZE 4096
enum CHECK_STATE {
CHECK_STATE_REQUESTLINE = 0,
CHECK_STATE_HEADER
};
enum LINE_STATUS {
LINE_OK = 0,
LINE_BAD,
LINE_OPEN
};
enum HTTP_CODE {
NO_REQUEST,
GET_REQUEST,
BAD_REQUEST,
FORBIDDEN_REQUEST,
INTERNAL_ERROR,
CLOSED_CONNECTION
};
static const char *szret[] = {"I get a correct result\n", "Something wrong\n"};
LINE_STATUS parse_line(char *buffer, int &checked_index, int &read_index) {
char temp;
for (; checked_index < read_index; ++checked_index) {
temp = buffer[checked_index];
if (temp == '\r') {
if ((checked_index + 1) == read_index) {
return LINE_OPEN;
}
else if (buffer[checked_index + 1] == '\n') {
buffer[checked_index++] = '\0';
buffer[checked_index++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
else if (temp == '\n') {
if ((checked_index > 1) && buffer[checked_index - 1] == '\r') {
buffer[checked_index - 1] = '\0';
buffer[checked_index++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
return LINE_OPEN;
}
HTTP_CODE parse_requestline(char *temp, CHECK_STATE &checkstate) {
char *url = strpbrk(temp, "\t");
if (!url) {
return BAD_REQUEST;
}
*url++ = '\0';
char *method = temp;
if (strcasecmp(method, "GET") == 0) {
printf("The request method is GET\n");
} else {
return BAD_REQUEST;
}
url += strspn(url, "\t");
char *version = strpbrk(url, "\t");
if (!version) {
return BAD_REQUEST;
}
*version++ = '\0';
version += strspn(version, "\t");
if (strcasecmp(version, "HTTP/1.1") != 0) {
return BAD_REQUEST;
}
if (strncasecmp(url, "http://", 7) == 0) {
url += 7;
url = strchr(url, '/');
}
if (!url || url[0] != '/') {
return BAD_REQUEST;
}
printf("The request URL is:%s\n", url);
checkstate = CHECK_STATE_HEADER;
return NO_REQUEST;
}
HTTP_CODE parse_headers(char *temp) {
if (temp[0] == '\0') {
return GET_REQUEST;
} else if (strncasecmp(temp, "Host:", 5) == 0) {
temp += 5;
temp += strspn(temp, "\t");
printf("the request host is:%s\n", temp);
} else {
printf("I can not handle this header\n");
}
return NO_REQUEST;
}
HTTP_CODE parse_content(char *buffer, int &checked_index, CHECK_STATE &checkstate, int &read_index, int &start_line) {
LINE_STATUS linestatus = LINE_OK;
HTTP_CODE retcode = NO_REQUEST;
while ((linestatus = parse_line(buffer, checked_index, read_index)) == LINE_OK) {
char *temp = buffer + start_line;
start_line = checked_index;
switch (checkstate) {
case CHECK_STATE_REQUESTLINE: {
retcode = parse_requestline(temp, checkstate);
if (retcode == BAD_REQUEST) {
return BAD_REQUEST;
}
break;
}
case CHECK_STATE_HEADER: {
retcode = parse_headers(temp);
if (retcode == BAD_REQUEST) {
return BAD_REQUEST;
} else if (retcode == GET_REQUEST) {
return GET_REQUEST;
}
break;
}
default: {
return INTERNAL_ERROR;
}
}
}
if (linestatus == LINE_OPEN) {
return NO_REQUEST;
} else {
return BAD_REQUEST;
}
}
int main(int argc, char *argv[]) {
if (argc <= 2) {
printf("usage:%s ip_address port_number\n", basename(argv[0]));
return 1;
}
const char *ip = argv[1];
int port = atoi(argv[2]);
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton(AF_INET, ip, &address.sin_addr);
address.sin_port = htons(port);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
assert(listenfd >= 0);
int ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int fd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);
if (fd < 0) {
printf("errno is:%d\n", errno);
} else {
char buffer[BUFFER_SIZE];
memset(buffer, '\0', BUFFER_SIZE);
int data_read = 0;
int read_index = 0;
int checked_index = 0;
int start_line = 0;
CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE;
while (1) {
data_read = recv(fd, buffer + read_index, BUFFER_SIZE - read_index, 0);
if (data_read == -1) {
printf("reading failed\n");
break;
} else if (data_read == 0) {
printf("remote client has closed the connection\n");
break;
}
read_index += data_read;
HTTP_CODE result = parse_content(buffer, checked_index, checkstate, read_index, start_line);
if (result == NO_REQUEST) {
continue;
} else if (result == GET_REQUEST) {
send(fd, szret[0], strlen(szret[0]), 0);
break;
} else {
send(fd, szret[1], strlen(szret[1]), 0);
break;
}
}
close(fd);
}
close(listenfd);
return 0;
}
|
书中说这里有两个状态机, 分为主状态机和从状态机, 从状态机用于解析出一行的内容, 主状态机用于根据当前状态选择不同的处理函数.
提高服务器性能的其他建议
池
以空间换时间, 即“浪费”服务器的硬件资源, 以换取其运行效率, 这就是池(pool)的概念。
池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源分配。当服务器进入正式运行阶段,即开始处理客户请求的时候,如果它需要相关的资源,就可以直接从池中获取,无须动态分配。很显然,直接从池中取得所需资源比动态分配资源的速度要快得多,因为分配系统资源的系统调用都是很耗时的。当服务器处理完一个客户连接后,可以把相关的资源放回池中,无须执行系统调用来释放资源。从最终的效果来看,池相当于服务器管理系统资源的应用层设施,它避免了服务器对内核的频繁访问。
根据不同的资源类型,池可分为多种,常见的有内存池、进程池、线程池和连接池。
内存池通常用于socket的接收缓存和发送缓存。对于某些长度有限的客户请求,比如HTTP请求,预先分配一个大小足够(比如5000字节)的接收缓存区是很合理的。当客户请求的长度超过接收缓冲区的大小时,我们可以选择丢弃请求或者动态扩大接收缓冲区。
进程池和线程池都是并发编程常用的“伎俩”。当我们需要一个工作进程或工作线程来处理新到来的客户请求时,我们可以直接从进程池或线程池中取得一个执行实体,而无须动态地调用fork或pthread_create等函数来创建进程和线程。
连接池通常用于服务器或服务器机群的内部永久连接。每个逻辑单元可能都需要频繁地访问本地的某个数据库。简单的做法是:逻辑单元每次需要访问数据库的时候,就向数据库程序发起连接,而访问完毕后释放连接。很显然,这种做法的效率太低。一种解决方案是使用连接池。连接池是服务器预先和数据库程序建立的一组连接的集合。当某个逻辑单元需要访问数据库时,它可以直接从连接池中取得一个连接的实体并使用之。待完成数据库的访问之后,逻辑单元再将该连接返还给连接池。
数据复制
应当避免不必要的数据复制, 这就在要求我们善用内核处理函数, 例如sendfile, splice, tee等, 这些函数都是在内核空间中直接进行, 避免了向用户空间的拷贝. 当然共享内存也是一个很有用的手段.
上下文切换和锁
我们知道进程切换和线程切换也是会导致系统开销的, 使工作线程的数量保持在一个合理的范围内也是一个必要的行为.
另外还有锁, 锁会带来大量的系统开销, 所以要善用读写锁等锁机制.